COCRE 1기 회원으로서 작성한 글입니다.

COCRE가 궁금하다면! 클릭!
안녕하세요! 코크리 1기, 알버트의 이상한 연구소의 이한울이라고 합니다. 이번 에피소드는 정상성(Stationarity)에 대한 내용입니다. 정상성, 혹시 들어보셨나요? 들어보지 않으셨어도 괜찮습니다. 이번 글에서는 정상성이란 무엇이며, 정상성은 어떻게 판단하며, 비정상적(non-stationary) 시계열을 어떻게 정상적으로 만들 수 있는가에 대해 이야기 해보려고 합니다.
정상성이 왜 필요한가?에 대해서는 이전 글에서 다룬 부분을 인용하여 가져오겠습니다.
만약 시계열의 특징이 관측된 시간과 무관하지 않다면, 해당 시계열은 시간에 따라 특징이 변하고 있다고 볼 수 있습니다. 지금 현재 시간이 t라고 할 경우, t-10~t-1까지 관측되었던 시계열의 특징이 t ~ t+10과 동일하지 않다는 것이죠. 이런 경우에 우리는 과연 t-10 ~ t-1 시점을 관측하여 얻어낸 모델을 t ~ t+10 시점에 적용할 수 있을까요?
아마 어려울 겁니다. 그렇기에 해당 에피소드에서는 어떤 시계열이 정상적(Stationary)이며, 정상적이지 않은 시계열은 어떻게 정상적으로 만들 수 있을지 이야기 해 볼 것입니다.
Chapter 0. 정상성을 이야기 하기 전에
시계열 데이터의 기본적인 특징은 특정 시점의 값(Xt)이 다른 시점의 값과 특정한 방식으로의 연관을 가지고 있다는 것입니다. 다시 말하자면, 각 값이 서로 완전히 독립적이지 않다는 것이겠죠. 시계열 분석은 이런 서로 연관된 값들의 관계를 파악하는 것이라고 할 수 있습니다.
통계적 시계열 분석에서, 우리는 어떤 확률 과정(Stochastic process)을 따르는 시계열이 있다고 가정하고 그 통계적 과정으로 부터 나타난 표본(Sample)을 통해 그 통계적 과정을 알아내고자 합니다. 하지만 통계적 과정을 정확하게 알아내는 것은 매우 어려우며, 우리는 이를 해결하기 위해 강한 가정(assumption)을 바탕에 깔아두어야 합니다. 정상성이란 이런 강한 가정 중 하나입니다.
Chapter 1. 정상성의 개념
자세한 정의를 보기 이전에 정상성에 대한 감부터 잡아보도록 하겠습니다.
정상성을 지니고 있는 확률 과정, 즉 정상 과정(Stationary Process)에 대해 위키피디아에서는 어떻게 정의하고 있을까요?

여러가지 어려운 말들이 많이 적혀있네요. 몇가지 키워드를 통해서 정상 과정에 대해 느껴보도록 합시다. 가장 중요한 키워드는 '시간에 상관없이'라는 부분입니다. 즉, 어떤 실체가(여기서는 확률변수 간의 확률 분포겠죠!) 시간에 상관없이 일정한 성질을 띠고 있는 것이 바로 정상 과정이라는 녀석인 것이죠! 그리고 이 성질이 바로 우리가 알아야 하는 것인 정상성입니다.
그렇다면 정상성의 엄밀한 정의로 천천히 들어가보도록 하겠습니다. 정상성에는 강 정상성(Strong/Strictly Stationary)과 약 정상성(Weakly/Second-order Stationary)이 있습니다. 대부분 강 정상성을 만족하는 시계열은 약 정상성을 만족합니다.(다만 iid Cauchy 분포 등의 예외가 있습니다)
강 정상성의 정의는 다음과 같습니다.

강정상성을 띠는 시계열은 모든 적률(moments)이 시간과 무관하게 일정합니다.(적률을 모르는 경우엔 이 부분은 넘기셔도 좋습니다)
조금 더 쉽게 말하자면, 기저를 이루는 확률 분포(Underlying distribution)가 언제나 같아야 한다는 것입니다. 이런 경우는 현실에서 매우 찾아보기 어렵습니다. 우리가 마주하는 데이터들은 항상 잡음(noise)도 존재하고 다양한 원인들이 서로 여러가지 영향을 미치고 있습니다. 그렇기에 어떤 시계열이 완벽하게 처음부터 끝까지 같은 확률 분포를 유지하는 경우는 드뭅니다.
또한 강정상 시계열을 발견했다고 하더라도 이를 수리적으로 증명하는 것은 더욱 어렵습니다.
그렇기에 우리에게 필요한 것은 바로 약 정상성입니다.

위에서 함께 보았던 정상 과정의 위키피디아 정의를 바탕으로 본다면, 어떻게 쉽게 이해할 수 있을까요!
수식을 보는 것을 좋아하는 분은 아마 거의 없을 테지만, 그래도 이해를 위해 수식을 잠깐 살펴보도록 하겠습니다.
임의의 t은 임의의 시점을 의미하는 것입니다. 임의의 t에 대하여 E(Xt)가 어떤 값이라는 의미는 어느 시점을 뽑아서 보더라도 기댓값이 같다는 의미입니다. Var(Xt) 역시 이를 바탕으로 이해하시면 됩니다. 정의의 3번 조건은 Xt와 Xt+h간의 공분산이 r(h)라고 나타나있습니다. 이는 어느 시점에 t를 뽑아도, 두 시점간의 공분산은 그 시간적 차이에만 의존한다고 이해할 수 있습니다.
이해가 조금 어려웠을까요?
이를 쉽게 한 문장으로 표현하자면 '약 정상성을 띠는 시계열 데이터는 어느 시점(t)에 관측해도 확률 과정의 성질(E(Xt), Var(Xt))이 변하지 않는다'라고 할 수 있을 것 같습니다.
저희는 이런 두 정상성의 정의 중, 약 정상성을 기본으로 하여 이야기를 진행해가도록 하겠습니다!
Chapter 2. 시각적으로 정상성 파악하기
정상성이 뭔지는 알겠는데, 정상적인 시계열은 도대체 어떻게 판단할 수 있지? 어떻게 생긴거야?
분명 이 글을 읽으시는 분들 중에서는 정상성의 정의만 보고도 정상 시계열을 머리속으로 그리실 수 있는 분들이 있을 테지만, 이 시리즈는 기초통계학 수준의 지식만 가진 분들도 이해할 수 있게 하기 위한 글이기 때문에 함께 시각적으로 정상성을 파악해보도록 하겠습니다.

시계열 분석과 예측에 있어서 가장 유명한 책 중 하나인 Forecast : Principles and Practice에 있는 예시를 가지고 왔습니다. 여기에는 총 9가지의 시계열 그래프가 나타나 있습니다.
각 그래프가 무엇을 나타내는지부터 함께 같이 살펴봅시다.
(a) 200 거래일 동안의 구글 주식 가격
(b) 200 거래일 동안의 구글 주식 가격의 일일 변동
(c) 미국의 연간 파업 수
(d) 미국에서 판매되는 새로운 단독 주택의 월별 판매액
(e) 미국에서 계란 12개의 연간 가격 (달러)
(f) 호주 빅토리아 주에서 매월 도살한 돼지의 전체 수
(g) 캐나다 북서부의 맥킨지 강 지역에서 연간 포획된 스라소니의 전체 수
(h) 호주 월별 맥주 생산량
(i) 호주 월별 전기 생산량
앞의 정상성의 정의를 곰곰이 생각해봅시다.
추세(Trend)가 있는 시계열은 정상적일 수 있을까요?
추세가 있는 시계열은 관측 시점에 따라 특성이 바뀌기 때문에 정상적일 수 없습니다.
그렇다면 계절성(Seasonality)이 있는 시계열은 정상적일 수 있을까요?
계절성이 있는 시계열도 관측 시점에 따라 특성이 변한다고 할 수 있습니다.
그 외에도 정의에 따라 분산이 증가하거나 감소하는 시계열 역시 정상적이라고 볼 수는 없습니다.
그렇다면 하나하나씩 정상적이지 않은 시계열을 골라내보도록 합시다.
먼저 추세가 있는 시계열들을 먼저 골라내보도록 하겠습니다. 구글 주식 가격(a), 미국의 연간 파업 수(c), 미국에서 계란 12개의 연간 가격(e), 도살된 돼지의 수(f), 호주 월별 전기 생산량(i)에서는 등락하는 확실한 추세가 보입니다.
계절성을 보이는 시계열도 많습니다. 미국의 단독주택 월별 판매액(d), 호주 월별 맥주 생산량(h), 호주 월별 전기 생산량(i)에서는 시각적으로도 뚜렷한 계절성이 보입니다.
남은 시계열은 구글 주식 가격의 일일변동(b)과 포획된 스라소니 수(g)입니다. 이 둘은 추세나 계절성을 보이지는 않습니다. 하지만 구글 주식 가격의 일일변동(b)에는 높게 솟아오르는 부분이 있습니다. 즉, 분산이 안정적이지 못하기 때문에 정상적이지 않을 수도 있습니다. (※하지만 솟아오르는 부분 앞까지는 확실히 정상적 시계열이라고 할 수 있습니다!)
결국 유일하게 정상적이라고 단언할 수 있는 시계열은 연간 포획된 스라소니의 전체 수(g) 하나 뿐입니다.
하지만 얼핏 보면, 스라소니의 전체 수(g) 데이터도 계절성을 지니고 있는 것처럼 보이기도 합니다. 하지만 이 시계열은 다른 계절성을 지닌 시계열들과 다르게 등락에 있어 고정된 기간이 존재하지 않습니다.
(계절성의 정의는 이전 글을 참고해주세요!)
이렇게 시계열 데이터에서의 추세와 계절성을 눈으로 식별하는 방법뿐만 아니라, ACF plot을 이용하여 비정상적 시계열임을 판단하는 방법도 있습니다. ACF plot에 대해 이야기하려면 자기회귀(Autoregression)에 대한 얘기가 반드시 필요하기 때문에, 이는 다음 글에 자세히 소개해드리도록 하겠습니다.
정상적 시계열은 생김새부터 다르게 생겼습니다.
하지만 데이터를 다루는 사람은 단순히 그래프만을 보고 '정상적이다!'라고 쉽게 말하지 않죠!
다음은 검정을 통한 정상성 판단에 대해 이야기해보도록 하겠습니다.
Chapter 3. 검정을 통해 정상성 판단하기
시계열 분석과 관련된 검정은 매우 많습니다. 이 모든것들을 글 하나에서 자세히 다룰 수는 없기 때문에, 이 챕터에서는 대표적인 검정 기법 몇개만 소개하도록 하겠습니다. 각 검정 방법들은 이 글에서 다루기에는 난이도가 높은 편입니다. 따라서 검정 방법은 '무엇을 검정하는지'(귀무가설이 무엇인지), '어떻게 사용하는지'(R이나 Python에서 사용)에 초점을 맞춰 말씀드리도록 하겠습니다.
KPSS(Kwiatkowski-Phillips-Schmidt-Shin) 검정
대부분의 정상성 검정은 단위근(Unit-root) 검정입니다. 단위근 검정이란 시계열의 확률적 추세 여부를 검정하는 것으로서 단위근의 존재 여부를 귀무가설로 둡니다. 단위근이 존재하는 경우, 그 시계열은 비정상 시계열입니다. 단위근에 대한 내용은 확률론 지식과 자기회귀(Autoregression)에 대한 선수지식이 필요한 내용이기 때문에, 관심있는 분들을 위해 Reference에 관련 문헌을 남겨두도록 하겠습니다.
KPSS 검정 역시 일종의 단위근 검정이지만, 다른 검정들과는 다르게 귀무가설이 '시계열 과정이 정상적(Stationary)이다'로 설정되어 있으며 대립 가설이 '시계열 과정이 비정상적(non-stationary)이다'로 설정되어 있습니다.
R에서는 tseries 패키지의 kpss.test를 이용하여 KPSS 검정을 할 수 있고, Python에서는 statsmodels 라이브러리에서 kpss를 import하여 사용하실 수 있습니다.
#R
library(tseries)
kpss.test(x, "level")(참조:https://www.rdocumentation.org/packages/tseries/versions/0.10-49/topics/kpss.test)
#Python
from statsmodels.tsa.stattools import kpss
kpss(data)(참조:https://www.statsmodels.org/stable/generated/statsmodels.tsa.stattools.kpss.html)
ADF(Augmented Dicky-Fuller) 검정
ADF 검정은 단위근(Unit-root) 검정입니다. 정상성을 판단할 때, ADF 검정은 KPSS와 함께 자주 활용됩니다. ADF 검정의 귀무 가설은 '시계열에 단위근이 존재한다' 이며, 대립가설은 '시계열이 정상성을 만족한다'입니다. R에서는 tseries 패키지의 adf.test를 이용하면 되고, python에서는 statsmodels 라이브러리에서 adfuller를 import하여 사용하실 수 있습니다.
일반적으로 정상성 검정에 있어서는 한가지 검정만을 사용하지는 않고, 다양한 검정 방법을 사용합니다. 여러분도 여러분의 분석 목적에 맞는 검정 방법을 잘 선택하여 사용하시면 됩니다!
#R
library(tseries)
adf.test(x)(참조:https://www.rdocumentation.org/packages/aTSA/versions/3.1.2/topics/adf.test)
#python
from statsmodels.tsa.stattools import adfuller
adfuller(data)(참조:https://www.statsmodels.org/dev/generated/statsmodels.tsa.stattools.adfuller.html)
KPSS 검정과 ADF 검정은 위의 라이브러리들을 이용하면 쉽게 수행됩니다. 하지만 출력결과를 해석하려면 또 추가적인 지식을 필요로 하겠죠. KPSS 검정과 ADF 검정의 방법론은 이 글에서 다를 수 있는 난이도를 훌쩍 뛰어넘습니다. 하지만 단순한 분석에서 결과를 쉽게 파악하고자 한다면, p-value를 중심적으로 보면 됩니다.
p-value는 유의확률이라고도 불립니다. 귀무가설(null hypothesis)이 관찰된 데이터의 통계치(statistics)와 양립할 수 있는지를 0부터 1까지의 숫자로 나타냅니다. 0에 가까울수록 통계치가 귀무가설과의 양립하는 정도가 낮습니다.
P-value를 통해 귀무가설을 기각(대립가설을 채택)하기 위해서, 우리는 기준을 둡니다. 이를 유의수준(significance level)이라고 부릅니다. 일반적으로 사용되는 값은 0.05나 0.01입니다. 유의수준은 (1- 신뢰도) 입니다. 그렇기에 유의수준으로 0.05를 이용했을때의 신뢰도는 0.95 (95%)라고 할 수 있겠지요.
현재 진행중인 분석의 중요도나 엄밀함에 따라서 0.05보다 느슨한(높은) 값을 기준으로 둘 수도 있고 0.01보다도 까다로운(낮은) 값을 기준으로 둘 수 있습니다.
예를 들어서 이해해봅시다. 우리는 어떤 시계열이 정상적인지 알고 싶고, 약 95%의 신뢰도로 이를 검정해보고 싶습니다. 그래서 ADF 검정을 이용하였고 출력값에 p-value가 0.06이 나왔습니다.
ADF 검정의 귀무가설은 '단위근이 존재한다' 였습니다. 그리고 단위근이 존재하면 비정상 시계열입니다. 우리는 95%의 신뢰도를 바탕으로 0.05라는 유의수준을 두었는데 출력값의 p-value는 이보다 높게 나왔습니다.
이 경우 우리는 귀무가설을 기각할 수 없습니다. 즉, 이 시계열이 정상 시계열이라고 결론 내릴 수 없습니다.
이런 방법으로 우리는 검정을 통해 정상 시계열임을 판단할 수 있습니다. 더 실전적인 예시는 아래 코드와 함께 살펴보실 수 있습니다!
Chapter 4. 어떻게 시계열을 정상적으로 만들 수 있을까?
지금까지 우리는 함께 정상성의 정의와 판단 방법에 대해 이야기했습니다. 이제 우리는 '어떤 시계열이 정상적인가?'에 대한 답을 할 수 있게 된 것이죠. 하지만 그 과정에서 모두 이런 생각이 드셨을 겁니다.
'와, 정상적인 시계열보다 비정상적인 시계열이 훨씬 많은데?'
맞습니다. 우리가 마주하는 많은 시계열 데이터들은 정상적이지 않습니다. 대부분의 통계적 시계열 모델들은 정상 시계열을 대상으로한 모델들인데, 그렇다면 정상적이지 못한 수 많은 데이터들은 어떻게 설명하고 예측할 수 있을까요?
방법은 매우 간단합니다. 비정상 시계열을 정상 시계열로 바꿔주면 됩니다. 앞의 예시에서 우리가 마주했던 비정상적 시계열들을 다시 한번 생각해볼까요?
비정상 시계열의 경우 대부분 추세가 있거나, 계절성이 있거나, 분산에 변동이 있었습니다. 그말은 즉, 추세를 제거하거나(detrending) 계절성을 제거하거나(deseasoning), 분산을 일정하게 만들면 그 시계열은 정상성을 띠게 된다는 것이죠.
분산을 일정하게 만드는 것은 다들 기초 통계학에서 배우셨을텐데요, Log Transformation이 대표적인 예시가 될 것 같습니다. 그러면 나머지 요소를 제거하는 방법에 대해 깊게 이야기해봅시다.
추세와 계절성을 제거하기 위한 방법으로는 대표적으로 세가지 방법이 있습니다.
1. 회귀 분석(regression approach)
2. 평활법(smoothing)
3. 차분(differencing)
시계열 회귀 분석을 이용하면 우리는 나머지(residuals)로서 추세와 계절성이 제거된 시계열을 얻을 수 있습니다. 평활법도 마찬가지로 이용하게 된다면 나머지(residuals)로서 추세와 계절성이 제거된 시계열을 얻을 수 있습니다. 우리가 지난번 글에서 마주했던 시계열 분해(Time Series Decomposition)은 주로 평활법을 이용하여 시계열 요소(추세, 계절성)를 추출합니다. 그리고 정상 시계열을 나머지로 반환합니다.
이 두가지 방법 역시 중요한 방법이지만, 우리가 자세히 볼 것은 바로 차분(differencing)입니다.
차분이란 이어진 데이터들의 차이를 구하는 것입니다. 한번의 차이를 구하는 것을 1차 차분이라고 하며, 1차 차분값을 다시 차분하는 것을 2차 차분이라고 합니다. 이런식으로 차분은 데이터의 길이가 충분할 경우 여러번 수행될 수 있습니다. (하지만 대부분의 경우엔 1차 차분만으로 정상적인 시계열이 만들어지며, 2차 이상 차분을 할 경우 해당 데이터에 적합한 모델의 설명력이 낮아지며 데이터 소실이 커집니다)
차분을 수식으로 설명하면 다음과 같습니다.
간단하죠? t시점의 값에서 t-1시점의 값을 빼는 것입니다. 이를 통해 시계열 수준의 추세는 대부분 사라지게 됩니다. 이런 원리를 이용하여 계절성을 제거하기 위해서 계절성 차분(seasonal differencing)이 존재합니다.
여기에서 m은 시차의 길이입니다. 12일마다 계절성의 주기가 존재하는 경우 m의 자리에 12가 들어가게 되겠죠. 이렇게 차분 및 계절 차분을 통하여 우리는 비정상 시계열을 정상 시계열로 바꿀 수 있습니다.
왜 이런 차분을 거치면 시계열이 정상적으로 변하는 걸까요? 왜냐하면 대부분의 비정상적 시계열은 누적 과정(Integrated Process)이기 때문입니다. 정상적 시계열이 누적되어 비정상적 시계열을 이루었기 때문에, 다시 누적된 것을 차분해줌으로써 그 이면의 정상적 과정을 우리가 볼 수 있게 되는 것입니다.
Chapter 5. 실습 & 마치며
지금까지 우리는 정상성에 대해 간단히 배웠습니다. 하지만 어떤 개념이든 실제로 실습해보지 않으면 의미가 없겠죠!
Python을 통해 비정상 시계열을 정상 시계열로 만들고 시각화 한 뒤, ADF검정을 통해 시계열이 정상적인지 함께 확인해보도록 하겠습니다.
이전 글에서 예시로 보여드렸던 AirPassengers Dataset을 이용하도록 하겠습니다.
R에서는 기본 제공 데이터지만, Python에서는 기본 제공이 아니기 때문에 Kaggle에서 데이터를 다운받아 사용하도록 하겠습니다.
https://www.kaggle.com/rakannimer/air-passengers
Air Passengers
Number of air passengers per month
www.kaggle.com
간단히 데이터를 열어 살펴보도록 하겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller #ADF 검정
airpassengers = pd.read_csv('./data/AirPassengers.csv')
data = airpassengers['#Passengers'] #Passengers 부분만 사용하도록 하겠습니다
plt.plot(data)
plt.show()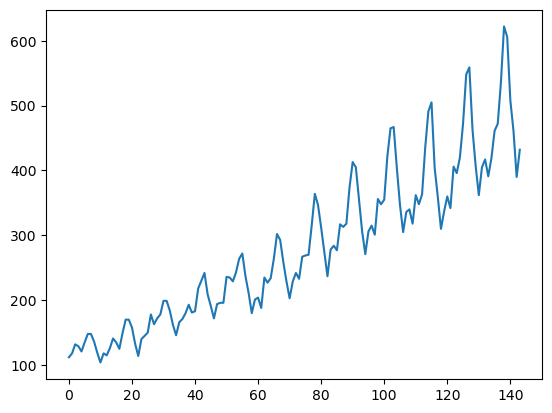
저번 글에서 봤던 AirPassengers 데이터의 plot입니다.
x축에 위치하고 있는 것은 '달'이고 y축에 위치하고 있는 것은 항공기 이용 승객 수입니다.
이 데이터는 분산도 커지고, 추세도 있고, 계절성도 있는 데이터입니다. 계절성은 '년(year)' 단위로 나타나고 있습니다. 시각적으로도 이미 충분히 정상적이지 않아 보입니다. ADF 검정을 통해 저희의 관측에 확신을 불어넣어 봅시다.
def adf_test(x):
stat, p_value, lags, nobs, crit, icb = adfuller(x) #adfuller 함수를 이용하면 6가지 output이 나옵니다
print('ADF statistics')
print(stat) #ADF 검정 통계량입니다
print('P-value')
print(p_value) #P-value입니다ADF statistics와 P-value만을 보여주는 간단한 함수를 작성하였습니다. 이를 통해 위 AirPassengers 데이터를 검정해보도록 하겠습니다.
adf_test(data)
> ADF statistics
> 0.8153688792060463
> P-value
> 0.991880243437641P-value가 0.99가 나왔습니다. 유의수준을 어떻게 잡더라도, 우리는 단위근이 존재한다는 귀무가설을 기각하기는 어려워 보입니다. 데이터는 정상적이라고 할 수 없습니다.
그러면 이 데이터를 한번 정상적으로 만들어보도록 하겠습니다.
AirPassengers 데이터는 분산이 커지고 있습니다. Log Transformation을 통해 이를 보정해주겠습니다.
AirPassengers 데이터는 추세가 있습니다. 1차 차분을 통해 추세를 제거해주도록 하겠습니다.
AirPassengers 데이터의 계절성 주기는 n=12(12개월)입니다. 계절 차분을 통해 계절성을 제거해주도록 하겠습니다.
data_transformed = np.log(data).diff().diff(12) #위의 순서대로 데이터를 변환하였습니다.
data_transformed = data_transformed.dropna() #차분으로 인해 생긴 데이터의 공백을 제거합니다.앞에서 제시한 수식을 떠올려보면, 차분을 진행할 때는 두 값을 빼주게 됩니다. 그렇기에 차분을 진행할 때마다 데이터의 길이가 짧아지게 되어, 짧아진 부분에 공백이 생깁니다. 이 공백을 지워주지 않으면 ADF 검정 과정에서 오류가 발생할 수 있습니다.
plt.plot(data_transformed)
plt.show()
여러 변환을 거쳤음에도 불구하고 시각적으로는 완전히 정상적으로 보이진 않습니다.
하지만 추세 및 계절성, 증가하는 분산이 제거된 것은 눈으로 직접 확인하실 수 있습니다.
adf_test(data_transformed)
> ADF statistics
> -4.443324941831113
> P-value
> 0.00024859123113841515ADF 검정 결과를 보면, 유의수준 0.01에서 '단위근이 존재한다'라는 귀무가설을 기각하고 '시계열은 정상적이다'라는 대립가설을 채택할 수 있습니다.
++참고)
R을 사용하는 분들을 위해 R코드를 일부만 첨부하겠습니다.
Python과 거의 유사합니다!
library(tseries) #adf.test를 불러옵니다
library(fpp2) #혹은 library(tidyverse)를 이용하셔도 됩니다.
data <- AirPassengers #R에서는 AirPassengers가 기본적으로 제공됩니다.
adf.test(data) #adf.test에 data를 넣으면 정리된 결과를 내보내줍니다.
data_transformed <- data %>% log() %>% diff() %>% diff(12)
#tidyverse나 fpp2에서는 '%>%'를 통해 연산 순서를 직관적으로 파악할 수 있습니다.
#data에 log를 취하고, 1차 차분과 계절 차분을 순서대로 진행해 줍니다.
plot(data_transformed)

위에서 보았던 것과 동일한 plot이 그려진 것을 보실 수 있습니다.
이렇게 저희는 시계열 모델을 만나기 전 마지막 관문인 정상성에 대한 공부를 마쳤습니다.
우리는 데이터를 정상적으로 만드는 과정을 통해서 데이터를 예측가능한 형태로 만들 수 있었습니다. 이제 다음엔 통계적 모델을 직접 적합시켜 봐야겠지요!
다음 시간에는 정상적인 시계열을 위한 모델인 AR, MA, ARMA 모델에 대해서 말씀드리고, 거기에 차분이 추가된 ARIMA와 계절 차분이 추가된 SARIMA까지 한번 다뤄보도록 하겠습니다.
글에 대한 피드백은 언제나 편하게 댓글로 남겨주세요. 읽어주셔서 감사합니다!
Reference
Ron J Hyndman and George Athanasopoilos - Forecasting: Principles and Practice, Chapter 9
Peter J.Brockwell and Richard A.Davis - Introduction to Time Series and Forecasting, Chapter 1, 6
Wikipedia - https://otexts.com/fpp3/stationarity.html (정상 과정)
Namuwiki - https://namu.wiki/w/%EC%8B%9C%EA%B3%84%EC%97%B4%20%EB%B6%84%EC%84%9D (강정상성,약정상성 정의)
http://pages.stern.nyu.edu/~churvich/Forecasting/Handouts/UnitRoot.pdf(단위근에 관한 추가 정보)
'이상한 연구실' 카테고리의 다른 글
| [A Short Survey Of NAVER AI NLP] 초기의 네이버 클로바 NLP 논문 읽기! (1) 2017년 (1) | 2022.06.03 |
|---|---|
| 딥러닝 전에, 알아보자 시계열 분석! - (1) 시작하자 시계열! - (4) | 2021.12.30 |