COCRE 1기 회원으로서 작성한 글입니다.

COCRE가 궁금하다면! 클릭!
딥러닝 전에, 알아보자 시계열 분석!
안녕하세요~ COCRE 1기, 알버트의 이상한 연구소 블로그의 이한울이라고 합니다.
이번 포스팅부터 시작하는 '딥러닝 전에, 알아보자 시계열 분석!'은 시계열 머신러닝/딥러닝을 시작하는 분들을 위한, 통계적 시계열 분석에 관한 콘텐츠 입니다.
이 시리즈는 통계적 시계열 분석의 역사와 내용, 그리고 시계열 데이터의 특징을 포괄적으로 다룸으로써 시계열 데이터 분석을 시작하는 분들에게 유용한 배경 지식을 제공하고자 합니다.
통계적 시계열 분석은 학습하기 위해 먼저 기초적인 회귀분석 지식 및 수리통계학에 대한 지식을 필요로 합니다. 하지만 이 시리즈는 고등학교 수준의 통계적 지식을 가진 분들도 쉽게 이해하실 수 있게 작성될 것입니다.
그러면 본격적으로 시계열 분석에 대해 알아보도록 할까요?
Episode 1. 시작하자 시계열!
Chapter 0. 왜 통계적 시계열 분석을 알아야 할까요?
'시계열 머신러닝, 시계열 딥러닝이 예측 성능이 훨씬 뛰어난데 왜 통계적 시계열 분석을 알아야 하지?'
많은 시계열 예측 작업에서 머신러닝과 딥러닝의 예측성능은 매우 뛰어납니다. 하지만 실무적 관점에서 통계적 시계열 분석 역시 중요한 위치를 차지하고 있으며, 많은 뛰어난 시계열 머신러닝 기법은 이런 통계학적 방법론과 결합된 형태를 띠고 있습니다. 이에 대해서는 Alieen Nielsen의 저서 Practical Time Series Analysis 의 일부분을 인용하여 말씀드리겠습니다.
산업용 시계열 분석은 위험이 낮은 분야에 적용하려고 노력합니다. 광고나 미디어 상품의 출시에 따른 이익을 예측하는 문제에서는 예측의 완전한 검증이 크게 중요하지 않습니다.......(중략)... 통계가 위험이 높은 예측에서 보다 근본적인 역할을 할 수 있기를 바랍니다.
...M4 대회는 시계열 대회로 100,000건의 시계열 데이터셋에 대한 정확도를 예측하는 것이 과제입니다. 이 대회의 우승자는 통계 모델과 신경망의 요소를 결합했습니다. 마찬가지로 준우승을 차지한 사람도 머신러닝과 통계 모두를 포함했습니다. 구체적으로는 통계 모델의 앙상블을 사용했지만.......(후략)
이렇듯, 시계열 통계 분석은 아직도 많은 시계열의 문제에서 중요한 위치를 차지하고 있습니다. 통계적 시계열 분석에 대한 지식은 시계열 머신러닝, 딥러닝 지식과 병행될 경우 매우 효과적입니다. 그리고 통계적 시계열 분석 자체로도, 높은 신뢰성이 요구되는 예측 작업에서 유용하게 사용될 수 있습니다.
chapter 1. 시계열 분석이 뭐죠?
시계열 분석이란, 시간 순서대로 정렬된 데이터에서 의미 있는 요약과 통계 정보를 추출하기 위한 노력을 의미합니다. 시계열 분석은 대부분 예측 과정에 많이 사용되지만, 과거의 행동을 진단하는 과정을 포함합니다.
한마디로 표현하자면,
과거가 미래에 어떤 영향을 주는가?
에 대한 해답을 찾아가는 것이 시계열 분석의 목적이라고 할 수 있습니다.
시계열 분석이 가장 광범위하게 사용되는 분야는 대표적으로 의학, 경제학, 기상학이 있습니다. 이 분야들의 주요한 문제들은 이런 시계열 분석의 목적과 일맥상통합니다. 그렇기에 이 학문들의 발전은 시계열 데이터의 축적 및 분석과 깊은 연관을 지니고 있습니다.
먼저 의학분야의 시계열 데이터 예시를 살펴볼까요?
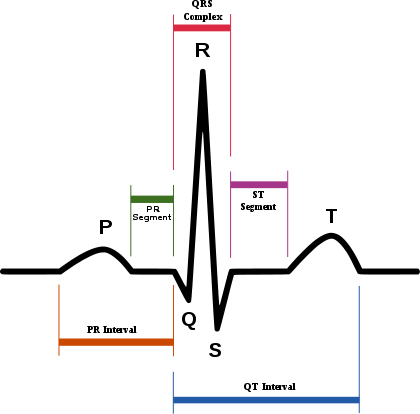
의학분야는 1662년 'Natural and Political Observations Made upon the Bills of Mortality'라는 저작부터 시작하여, 다양한 시계열 데이터가 축적되었고, 분석되었습니다. 그 ㄷ중에서도 가장 성공적인 시계열 분석의 대상은 바로 위 사진에 있는 ECG(혹은 EKG)데이터 입니다! 이는 전기 신호를 통해 심장의 상태를 진단하는 기술로, 심장 상태에 대한 정보를 시계열적으로 제시합니다.
ECG 데이터 만큼이나 유명한 경제 분야의 시계열 데이터도 있죠. 바로 주가 데이터도 시계열 데이터입니다.
주가와 관련된 시계열 분석의 문제는 수십, 수백년간 Finance 분야의 도전 과제였습니다.현재도 정말 많은 논문들이 매년 쏟아져 나오고 있습니다. 저희도 이후 포스팅에서, 이런 금융 시계열 분석의 특수한 기법들에 대해 다뤄 볼 예정입니다.
의학과 경제학 뿐만 아니라, 정말 다양한 분야에서 시계열 데이터와 시계열 분석은 중요한 위치를 차지하고 있습니다. 특히 통계적 시계열 분석의 시초가 되는 자기회귀(Autoregression)는 실험 물리학자인 우드니 율(Udny Yule)이 태양의 흑점 데이터를 분석하기 위해 사용되었던 것이었을 정도로, 자연과학 분야에서도 시계열 데이터와 시계열 분석은 아주 중요한 위치를 차지합니다.
chapter 2. 시계열 데이터의 구성요소
시계열 데이터는 몇가지 중요한 구성요소를 가지고 있습니다. 이를 확인해보기 위하여 R의 기본 제공 데이터인 AirPassengers 데이터를 살펴보도록 하겠습니다.

AirPassengers 데이터셋은 1949년부터 1960년까지의 월간 항공기 이용 승객수를 기록한 데이터셋입니다. 해당 데이터셋은 시계열 데이터로서 중요한 특성들을 가지고 있기 때문에, 다양한 시계열 분석 교육 자료에서 쉽게 만나보실 수 있습니다.
해당 plot을 보시면 몇가지 중요한 특징을 보실 수 있습니다. 먼저 눈에 띄는 것은 추세(Trend)가 있죠. 위 시계열 데이터는 뚜렷한 추세를 지니고 있습니다. (점점 상승하는 것이죠!) 또 다른 특징으로는 계절성(Seasonality)이 눈에 띕니다. 월별 데이터가 뚜렷한 주기를 지닌 상태로 등락을 거듭하는 것을 볼 수 있죠. 해당 데이터 셋에서는 없지만, 계절성과 유사한 주기성(Cycle)이라는 것도 있습니다. 이런 요소들을 시계열의 구성요소라고 부릅니다.
자세한 정의를 살펴보자면,
추세(Trend)란 장기적으로 증가하거나, 감소하는 경향성이 존재하는 것을 의미합니다.
계절성(Seasonality)이란 계절적 요인의 영향을 받아 1년, 혹은 일정 기간 안에 반복적으로 나타나는 패턴을 의미합니다.
주기성(Cycle)이란 정해지지 않은 빈도, 기간으로 일어나는 상승 혹은 하락을 의미합니다.
(주기성은 학자마다 조금씩 정의가 다르니, 참고로만 알아두시길 바랍니다)
시계열 분해(Time series decomposition)는 이런 시계열의 구성요소들을 쉽게 파악할 수 있도록 도와줍니다.
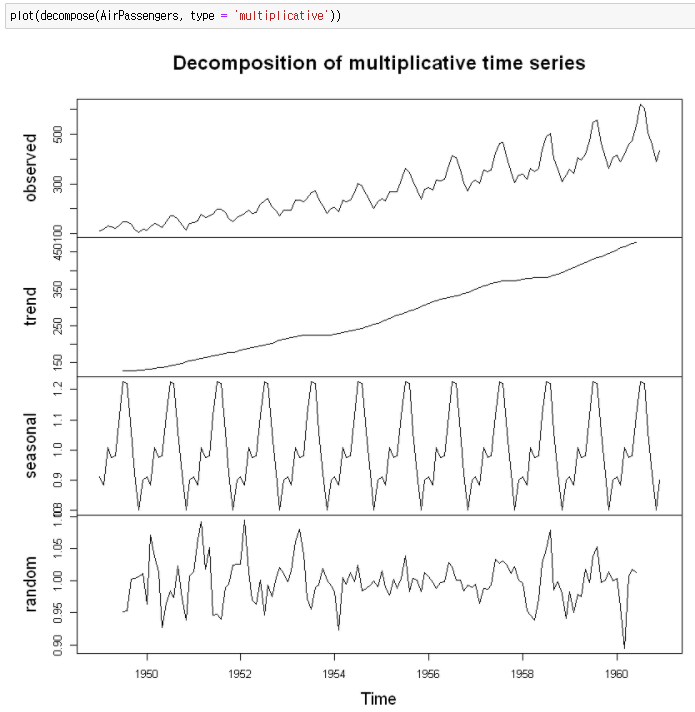
시계열 분해 plot을 보시면, 방금 전 우리가 데이터에서 확인했던 데이터의 구성 요소를 쉽게 파악하실 수 있습니다.
Plot의 마지막 줄에 있는 random은 앞의 시계열 분해 후 남는 나머지(residuals)를 의미합니다.
시계열 분석에서는 이 나머지 부분이 중요한데, 이 부분에 더이상 가진 정보가 없게(백색잡음(White Noise)이 되도록) 하는 것이 시계열 분석에서 매우 큰 부분을 차지하고 있기 때문이죠. 이것에 대해서는 Episode 2에서 더욱 자세히 다뤄볼 예정입니다.
이런 시계열 분해는 다양한 용도로 활용됩니다. 추세만을 연구하고 싶은 경우엔, 계절성을 제거한(Seasonally adjusted) 데이터를 활용할 수도 있겠죠!
시계열을 분해하는 방법론에는 여러가지가 있으며, 많은 국가기관(특히 미국의 국가기관)들은 기관의 분석 목적에 적합한 시계열 분해 기법을 활용합니다. 이 부분에 대한 내용은 꽤 방대하기 때문에, 관심있는 분들을 위하여 몇가지 예시를 알려드리며 이만 시계열 분해 part를 마치도록 하겠습니다.
여러 National Statistics Office들은 다음의 시계열 분해 방법론을 활용합니다
ABS -> X-12-ARIMA
US Census Bureau -> X-13-ARIMA-SEATS
Statistic Canada -> X-12-ARIMA
ONS(영국) -> X-12-ARIMA
EuroStat -> X-13-ARIMA-SEATS
chapter 3. 앞으로 함께 배워나갈 시계열 분석
앞으로 함께 학습할 시계열 분석의 내용들에 대해서 간략히 말씀드리려고 합니다. 앞에서도 말씀드렸듯, 통계적 시계열 분석은 많은 배경지식을 요구하고 그 내용도 많이 어렵습니다. 이 챕터에서는 앞으로 배울 내용들이 전체적인 통계적 시계열 분석에서 어떤 위치를 차지하고 있으며, 어떤 지식을 필요로 하는지 간략하게 말씀드릴 것입니다.
Episode 2. 정상성(Stationarity), 들어봤니?
해당 에피소드에서는 정상성(Stationarity)에 대한 개념을 차근 차근 함께 학습할 것입니다. 만약 통계적 시계열 분석을 처음 접한 분이라면 정상성이라는 개념을 아예 처음 들어보셨을 수도 있을 거라고 생각합니다.
정상성이란, 쉽게 말해서 '시계열의 특징이 관측된 시간과 무관하다'는 것을 의미합니다. 그렇다면 이것이 시계열 분석에서 어떤 의미가 있을까요?
만약 시계열의 특징이 관측된 시간과 무관하지 않다면, 해당 시계열은 시간에 따라 특징이 변하고 있다고 볼 수 있습니다. 지금 현재 시간이 t라고 할 경우, t-10~t-1까지 관측되었던 시계열의 특징이 t ~ t+10과 동일하지 않다는 것이죠. 이런 경우에 우리는 과연 t-10 ~ t-1 시점을 관측하여 얻어낸 모델을 t ~ t+10 시점에 적용할 수 있을까요?
아마 어려울 겁니다. 그렇기에 해당 에피소드에서는 어떤 시계열이 정상적(Stationary)이며, 정상적이지 않은 시계열은 어떻게 정상적으로 만들 수 있을지 이야기 해 볼 것입니다.
Episode 3. 시계열 분석의 대표, ARIMA
ARIMA 모델은 상당히 유명한 모델입니다. 아마 많은 분들이 박스-젠킨스법(Box - Jenkins)이나, Auto-Arima를 한번 쯤은 들어보셨을 거라고 생각합니다. ARIMA 모델은 AR(p)(Auto regression) 모델과 MA(q) (Moving Average) 모델, 그리고 차분(ARIMA의 'I'ntegration의 의미입니다)이 결합된 모형입니다. 말만 들으면 꽤 어려울 것 같죠!
AR(p) 모델과 MA(q) 모델은 앞에서 언급한 정상적인 상태에서 활용되는 모델이며, 차분이란 정상성을 만드는 방법 중 하나입니다. 그렇기에 ARIMA 모델을 이해하기 위해서는 앞 에피소드의 정상성을 꼭 이해하는 것이 중요합니다.
ARIMA는 1900년대 중반에 나온 모델이지만, 아직까지도 매우 높은 성능을 보여주고 있는 모델입니다. 아직까지도 많은 시계열 예측의 문제에서 ARIMA가 다른 시계열 분석 기법보다 뛰어난 성능을 보여주는 경우가 많습니다.
그리고 추가적으로 SARIMA 모델에 대해서도 살짝 배울 예정인데요, SARIMA의 S는 'Seasonal'입니다. 이 단어, 어디서 본 것 같지 않나요? 맞습니다! 앞에서 배운 계절성을 고려하는 모델이죠. ARIMA에 대한 지식을 바탕으로, SARIMA에 대해서는 간략하게 배워보도록 하겠습니다.
Episode 4. 아-취!(ARCH) 금융 시계열
금융 시계열은 다른 시계열 데이터에서 나타나지 않는 특별한 성질을 가지고 있습니다. 저희는 이런 금융 시계열의 특징을 바탕으로 금융 시계열을 위한 모델인 ARCH, 그리고 그 파생 모델인 GARCH에 대해 함께 배워볼 것입니다. ARCH는 금융 공학에서도 아주 특별한 위치를 차지하고 있는 모델이죠. 금융 분야에 관심이 있는 분이라면 이 에피소드가 더욱 재밌을 것입니다.
Episode 5. 그 외의 시계열 분석들
시계열 분석은 그 내용이 아주 넓고 방대합니다. 이번 시리즈는 아주 핵심적인 시계열 분석 모델만을 다루고자, 많은 내용들을 덜어낼 수 밖에 없었습니다. 하지만 이 에피소드에서는, 우리가 다루지 않은 다양한 시계열 분석 방법론들을 간략하게 소개하고 더 나아가 머신러닝과 결합된 통계 모델들까지 간단하게 소개하고자 합니다.
마치며
이번 에피소드에서는 통계적 시계열 분석의 필요성, 구성성분에 대해서 이야기하고 앞으로 우리가 배워갈 시계열 분석 방법들에 대한 소개가 있었습니다. 많은 분들이 해당 컨텐츠를 통해 통계적 시계열 분석에 대해 흥미와 기초적인 지식을 갖고, 앞으로 다양한 분야에 이런 지식을 활용할 수 있으면 좋겠습니다. 다들 읽어주셔서 감사합니다!
Reference
Ron J Hyndman and George Athanasopoilos - Forecasting: Principles and Practice, Chapter 6, Chapter 8
Alieen Nielsen - Practical Time Series Analysis, Chapter 1, Chapter 17
'이상한 연구실' 카테고리의 다른 글
| [A Short Survey Of NAVER AI NLP] 초기의 네이버 클로바 NLP 논문 읽기! (1) 2017년 (1) | 2022.06.03 |
|---|---|
| 딥러닝 전에, 알아보자 시계열 분석! - (2) 정상성(Stationarity), 들어봤니? - (1) | 2022.02.18 |