BERT + RoBERTa
Brief Introduction to BERT and RoBERTa
BERT
Abstract & Introduction

BERT는 Bidirectional Encoder Representations from Transformers의 줄임말로 Transformer의 Encoder architecture를 활용한 모델이다.
BERT는 양방향으로 unlabeled된 data를 학습하였으며, BERT는 단순히 additional한 one output layer를 추가함으로써 쉽게 fine-tuning할 수 있는 모델이다.
Pre-trained LM을 활용하는 전략은 현재 두가지가 있는데, 바로 feature-based와 fine-tuning이라고 할 수 있다. feature-based approach에는 대표적으로 ELMo가 있으며 fine-tuning approach에는 대표적으로 GPT-1이 있다. 하지만 GPT-1은 단순히 unidirectional(단방향)적이기 때문에 본 논문에서는 fine-tuning의 가능성을 전부 발휘하지 못하고 지적한다. BERT는 GPT의 이런 단점을 극복하고, ‘Masked Language Model(MLM)’ pretraining objective를 통해 더 나은 Pretrained 모델을 제공하고자 한다.
Model: BERT
BERT의 frame work는 크게 pretraining과 fine-tuning으로 나눠질 수 있다.
그전에 일단 아키텍쳐를 살펴보자
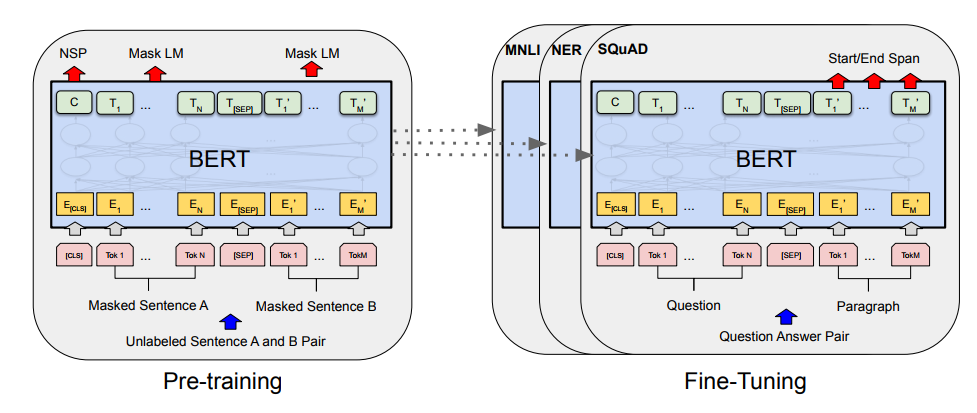
BERT의 Model Architecture는 전적으로 Vaswani의 Transformer(2017)의 Encoder에 의존하고 있다. BERT는 BERT-base 모델과 BERT-large모델로 구분된다. BERT-base 모델은 12개 Layer, 768개의 Hidden Size, 12개의 Attention Head를 지니고 있으며 총 1억 천만개의 parameter를 가지고 있다. BERT-large는 24개의 layer, 1024개의 Hidden Size, 16개의 Attention Head를 지니고 있으며 총 3억 4천만개의 parameter를 지니고 있다.
BERT의 input값으로는 단일 문장 뿐만 아니라 문장들의 pair 역시 들어간다.
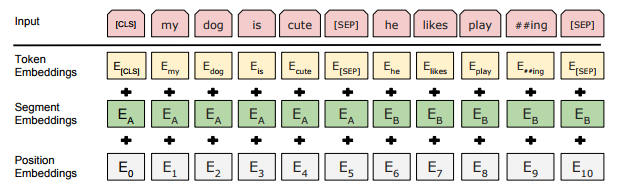
BERT는 30K 사이즈의 WordPiece Embeddings를 사용하여 Input값을 구성하는데 먼저 모든 sequence의 시작은 special token인 [CLS]가 들어간다.
그리고 Pair로 들어간 문장은 서로 구분되기 위해 그 사이에 [SEP]라는 special token을 삽입한다.
그렇게 만들어진 Token Embeddings는 segment와 positional Embeddings와 더해져 Input값을 구성하게 된다.
Pretraining BERT #MLM # NSP
#Task 1 : Masked LM
당시까지 standard conditional language model들은 left-to-right 아니면 right-to-left로만 학습을 진행하였다. BERT는 deep bidirectional representation을 학습시키기 위해 Masked LM을 이용하였다.
BERT는 input WordPiece Token의 15%에 랜덤하게 뽑고, 그 중에서 80%에 [MASK]토큰을 부여한다. 그리고 10%는 랜덤한 토큰으로 바꾸고 나머지 10%는 그대로 둔다. 그리고 Original Token을 예측하도록 하여 pretraining을 진행하게 된다.
#Task 2 : Next Sentence Prediction
Question-Answering이나 Natural Language Inference같은 Task에서는 두 문장간의 relationship을 이해하는 것이 중요하다. 이는 단순한 language modeling으로는 포착이 불가능하기 때문에, 문장 관계를 이해시키는 과정이 필요하다.
BERT는 Binarized next sentence prediction을 통해 이를 수행한다. BERT는 training example에서 A, B문장을 추출하는데 B문장에는 두가지 종류가 있다. 추출된 B 문장의 절반은 실제 다음 문장으로 IsNext라고 라벨링되며, 나머지 절반은 랜덤 추출된 다른 문장으로 NotNext로 라벨링된다. 이를 바탕으로 BERT는 다음 문장을 예측하는 pretraining과정을 거친다.
Fine-tuning BERT
단순히 task specific input과 output을 넣는 것으로 BERT는 쉽게 fine-tuning이 가능하다. sentence A, B를 Input으로 넣음으로써
(1) sentence pairs in paraphrasing
(2) hypothesis-premise pairs in entailment
(3) question-passage pairs in quesion answering
(4) degenerate text - 0 pair in text classification or sequence tagging을 수행한다.
Output으로는 token-level task(sequence tagging)에서는 token representation이 나오며 classification(entailment, sentiment analysis)에서는 CLS representation이 나온다.
위의 영상을 통해 시각적으로 BERT의 input, architecture, output을 확인할 수 있다.
Experiment & Results
BERT는 많은 Benchmark에서 state-of-art의 성능을 보여주었다.
1) GLUE

2) SQUAD 1.1 + 2.0


3) SWAG

+ RoBERTa
Abstract & Introduction

Language Model Pretraining에는 많은 비용이 소모된다.
Yinhan et al은 key hyperparameter 조정 및 training data size 조정을 하던 중 BERT가 significant하게 undertrained 되었다는 사실을 발견했다. 그리고 그들은 undertrained의 문제를 해결하여 높은 성과를 냈다.
이들이 modify한 것은 크게 네가지다.
(1) 모델을 더 긴 시간, 큰 배치로, 많은 데이터로 학습시켰다.
(2) NSP 태스크를 없앴다.
(3) 더 긴 sequence를 학습시켰다
(4) 동적으로 바뀌는 masking pattern을 추가하였다.
Why Larger Batches?
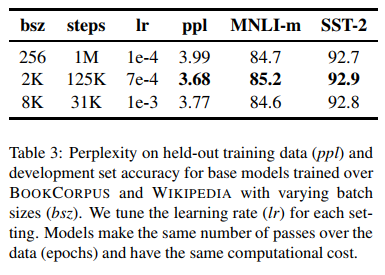
기존의 NMT 논문들은 Large Mini-batch가 optimization speed와 end-task performance에 효과적이라는 것을 입증하였으며, You et al은 BERT 역시 이런 large batch training이 가능하다는 것을 보여주었다.
BERT-base 실험 결과 batch size가 커질수록 MLM objective에 대한 perplexity가 올라갔으며 end-task accuracy도 증가하였다.
Why No NSP? + Why Full Sentence?
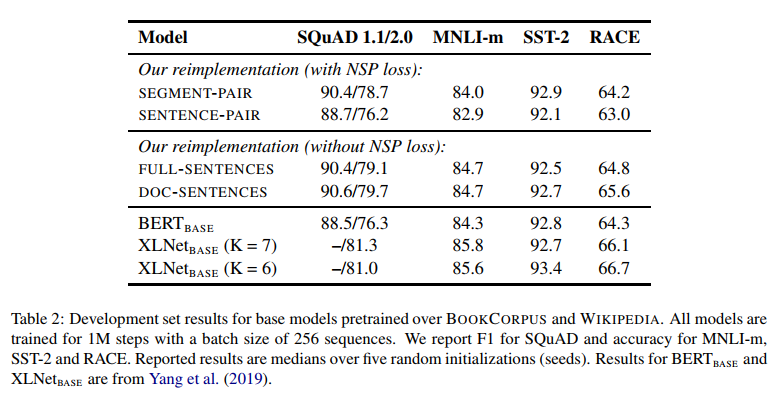
BERT에서는 NSP가 중요한 pretraining task였으나 Lample and Cooneau. 2019, Yang et al. 2019, Joshi et al. 2019에서 꾸준히 NSP의 필요성에 대한 문제 제기가 있었고, RoBERTa는 이를 실험적으로 검증하기 위해 여러 실험환경을 구성하여 NSP의 필요성을 확인해보았다.
위 표를 보면 BERT와 유사하게 Segment/Sentence Pair + NSP Loss로 Pretrain을 시킨 모델이 제시되어 있다. 그리고 그 아래는 RoBERTa에서 NSP Loss 없이 full sentence(cross document), 혹은 documentation(not cross document)을 학습시키는 방법을 취했다.
그리고 실험 결과, NSP를 제거하는 방식이 downstream task performance를 증가시키는 것으로 나타났다. 그리고 RoBERTa는 가장 높은 성능이 나온 Doc-Sentences 모델을 활용하게 되었다.
Why Dynamic Masking?
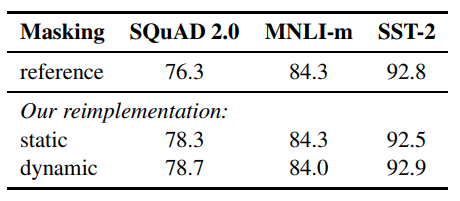
BERT는 MLM을 data preprocessing 과정에 수행하였는데, 여기선 이를 static mask라고 지칭하였다. 같은 mask를 자주 학습하는 것을 피하기 위해 BERT는 이를 10번 복사하여 다른 방식으로 mask를 부여하고 40번의 training을 하였다. 그래서 결국 같은 mask가 4번씩 학습을 진행하게 되는 결과를 초래했다.
그래서 RoBERTa는 매 학습마다 masking pattern이 달라지는 MLM을 사용하였다. 그 결과 위 표처럼 약간 나은 결과를 얻게 되었다.
Larger byte-level BPE?
기존의 BERT는 30K사이즈의 character-level의 BPE를 활용하였다. Byte-level의 BPE을 활용할 경우, BERT는 subword vocabulary까지 학습할 수 있는 장점을 지니고 있고 ‘Unknown Token’에 대해 더 잘 처리할 수 있게 도와준다. RoBERTa는 50K subword unit으로 이루어진 byte-level BPE를 활용함으로서, BERT-base에는 15M개의 파라미터를, BERT-large에는 20M의 additional parameter를 더해주게 된다. (Embedding의 차원이 커지기 때문에)
이런 과정 통해 RoBERTa는 BERT및 여러 BERT 파생 모델들을 이기고 state-of-art의 결과를 보여주었다!
Reference
Jacob Devlin et al. - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Yinhan et al. - RoBERTa: A Robustly Optimized BERT Pretraining Approach